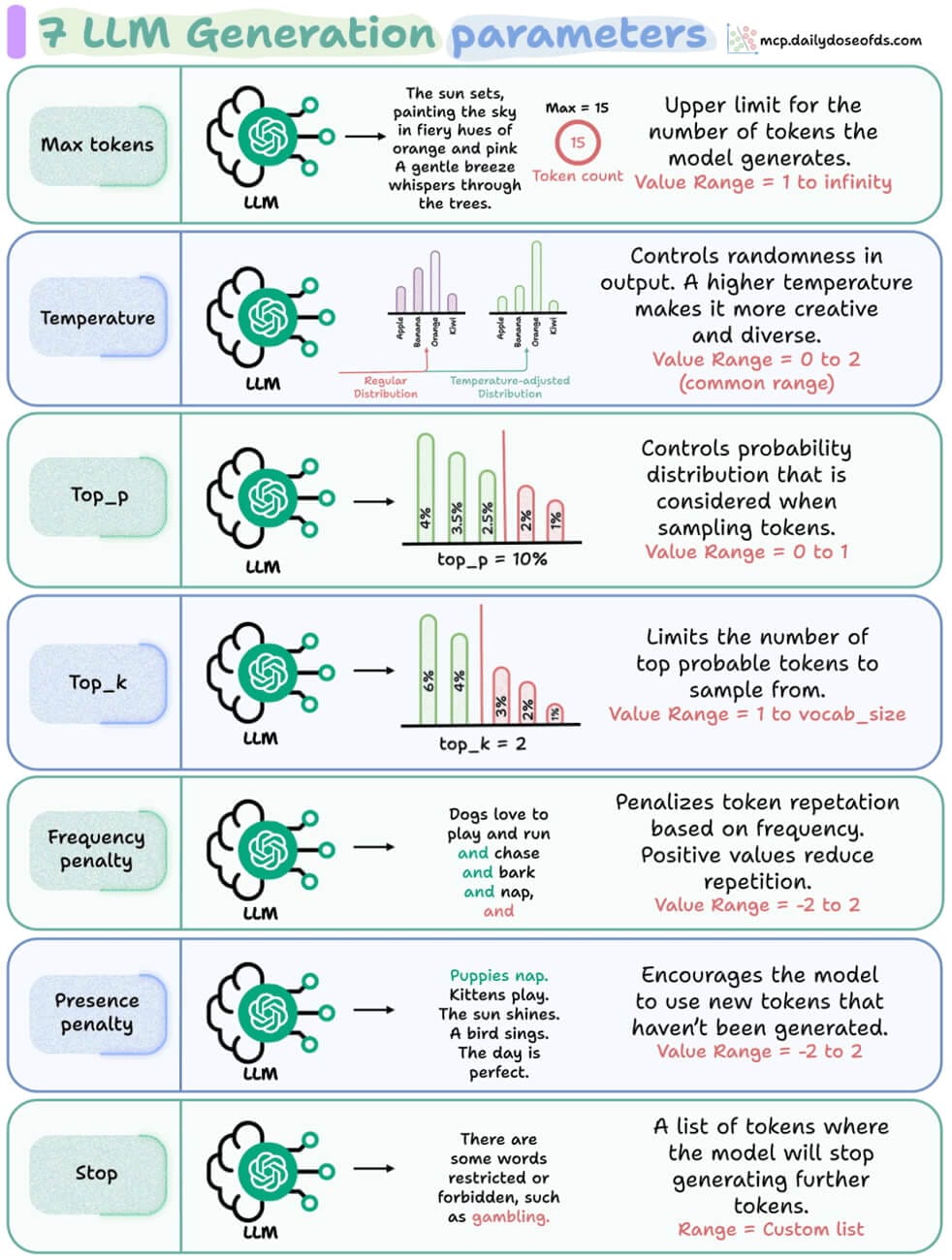
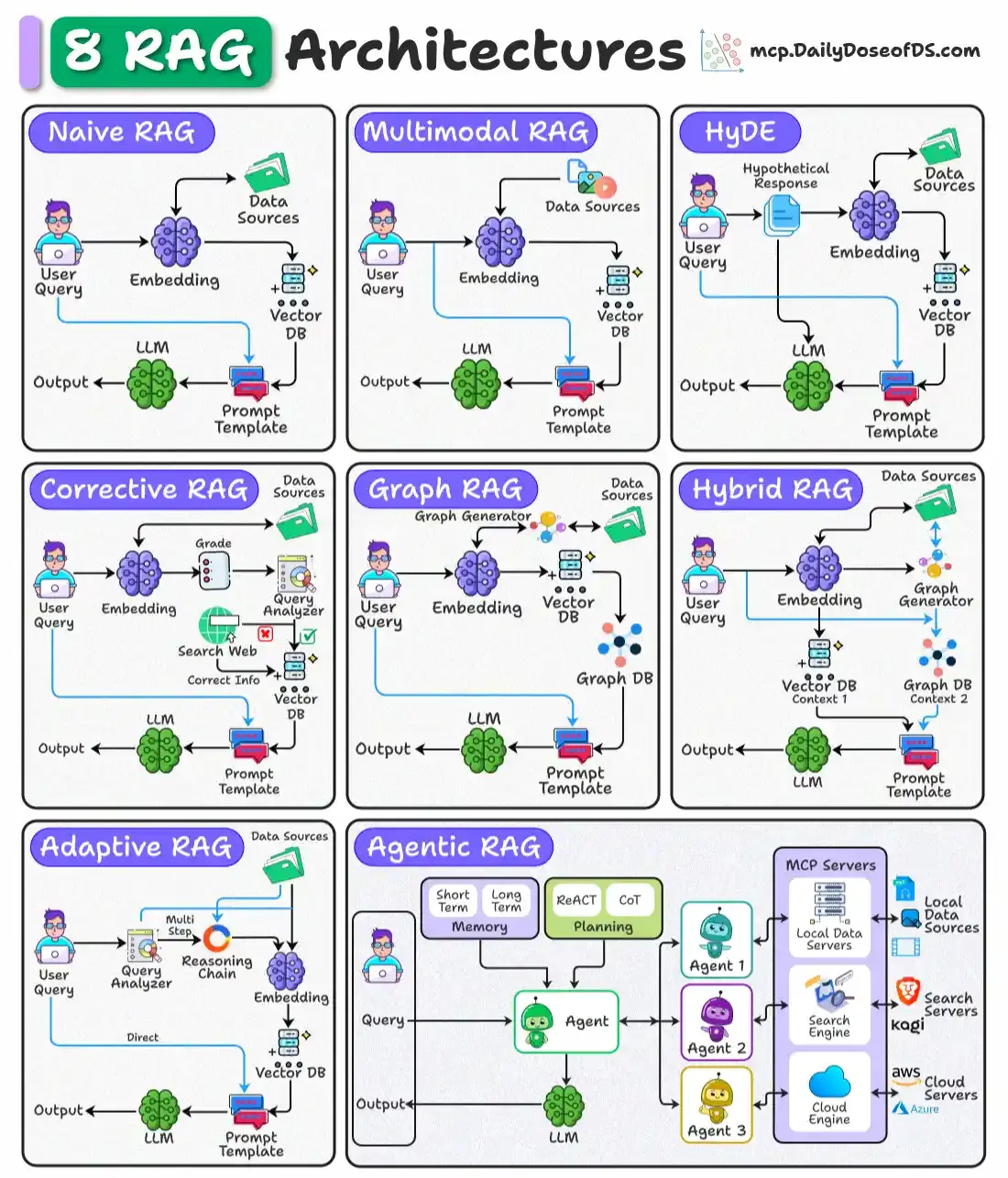
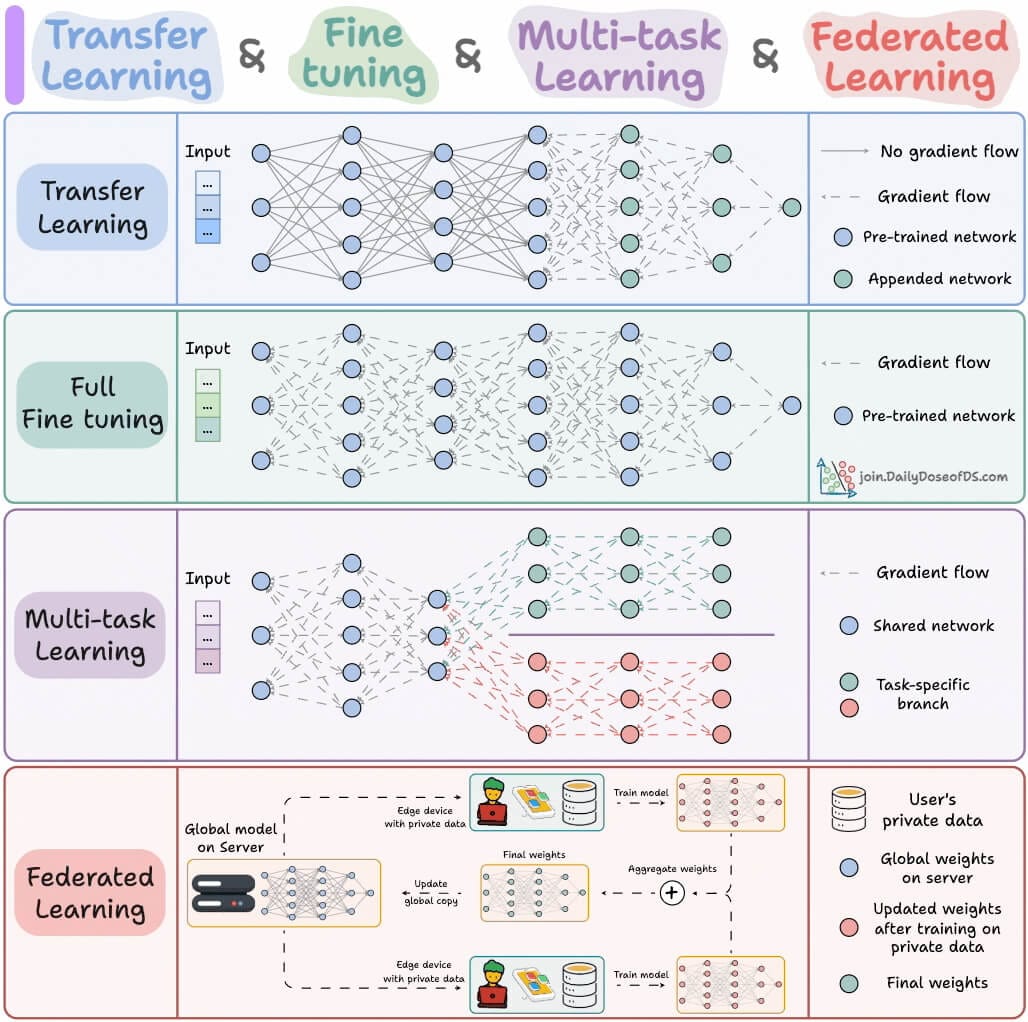
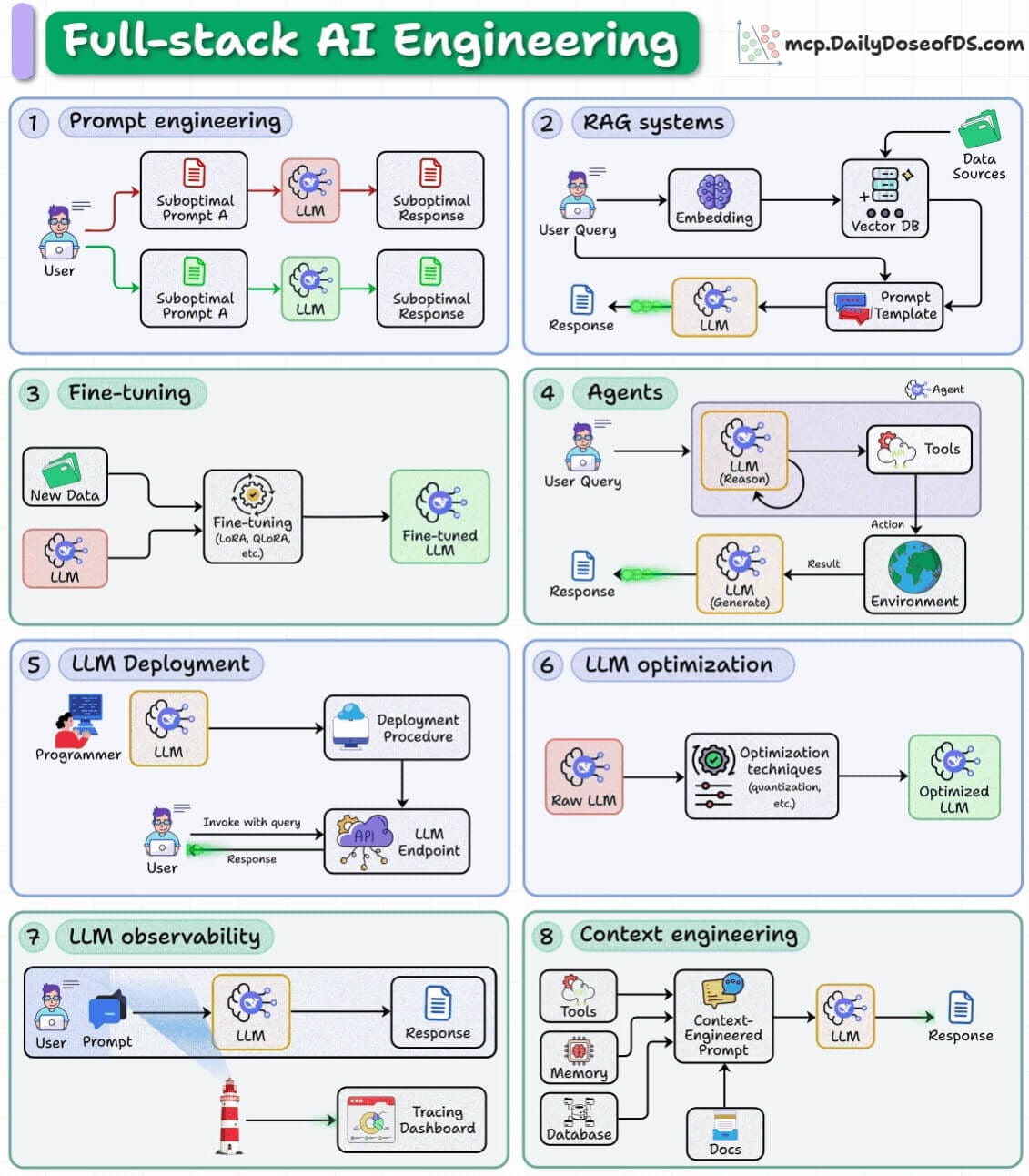
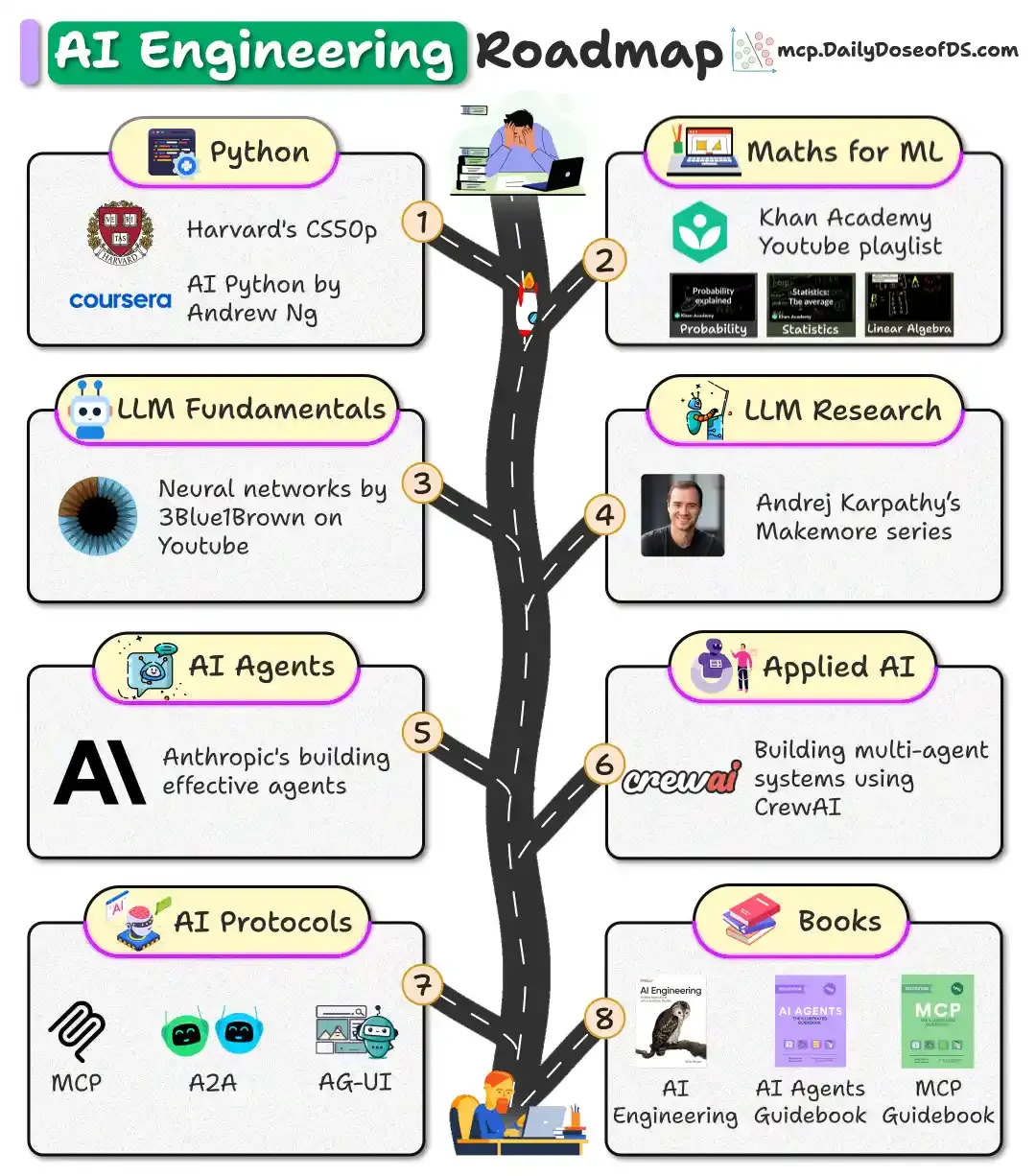
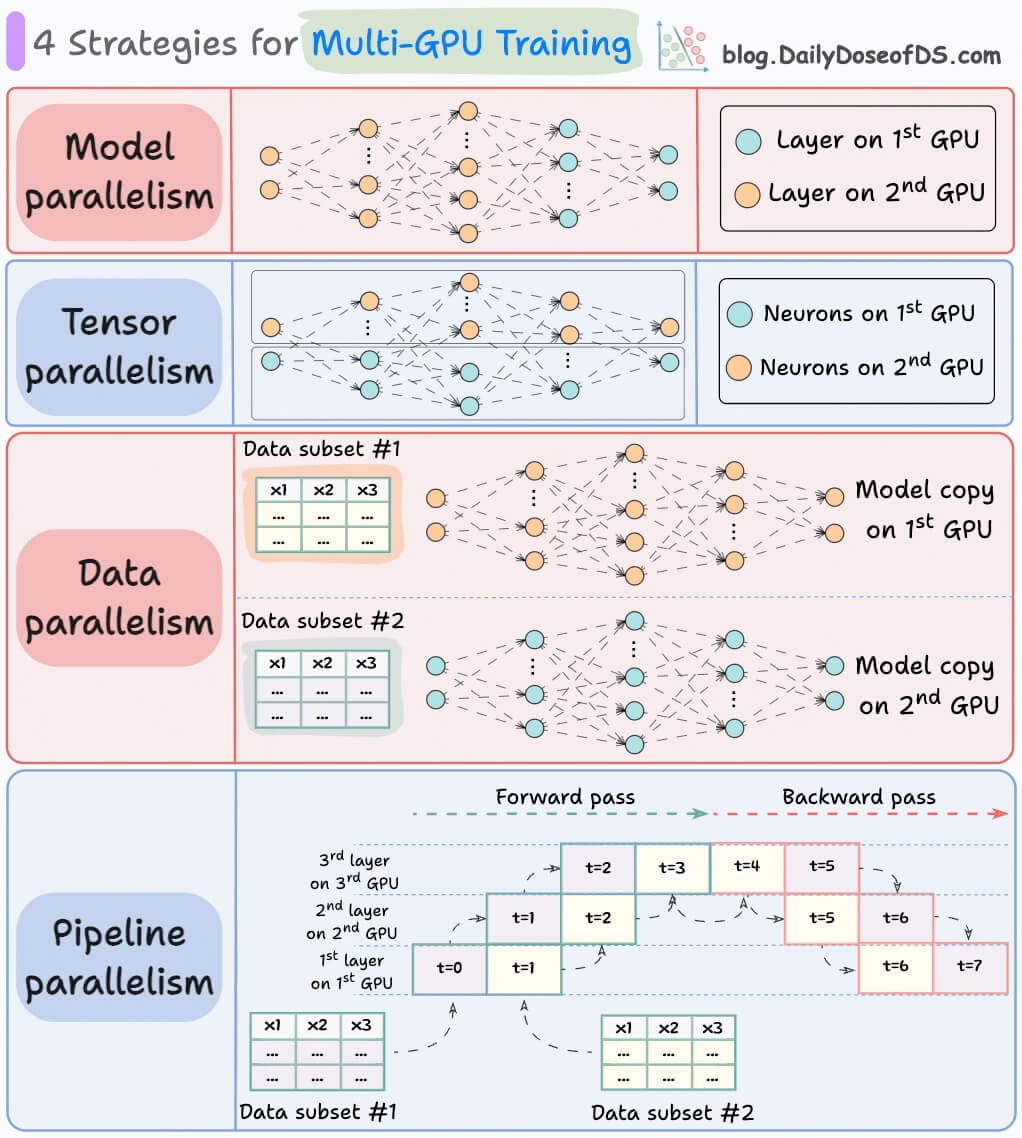
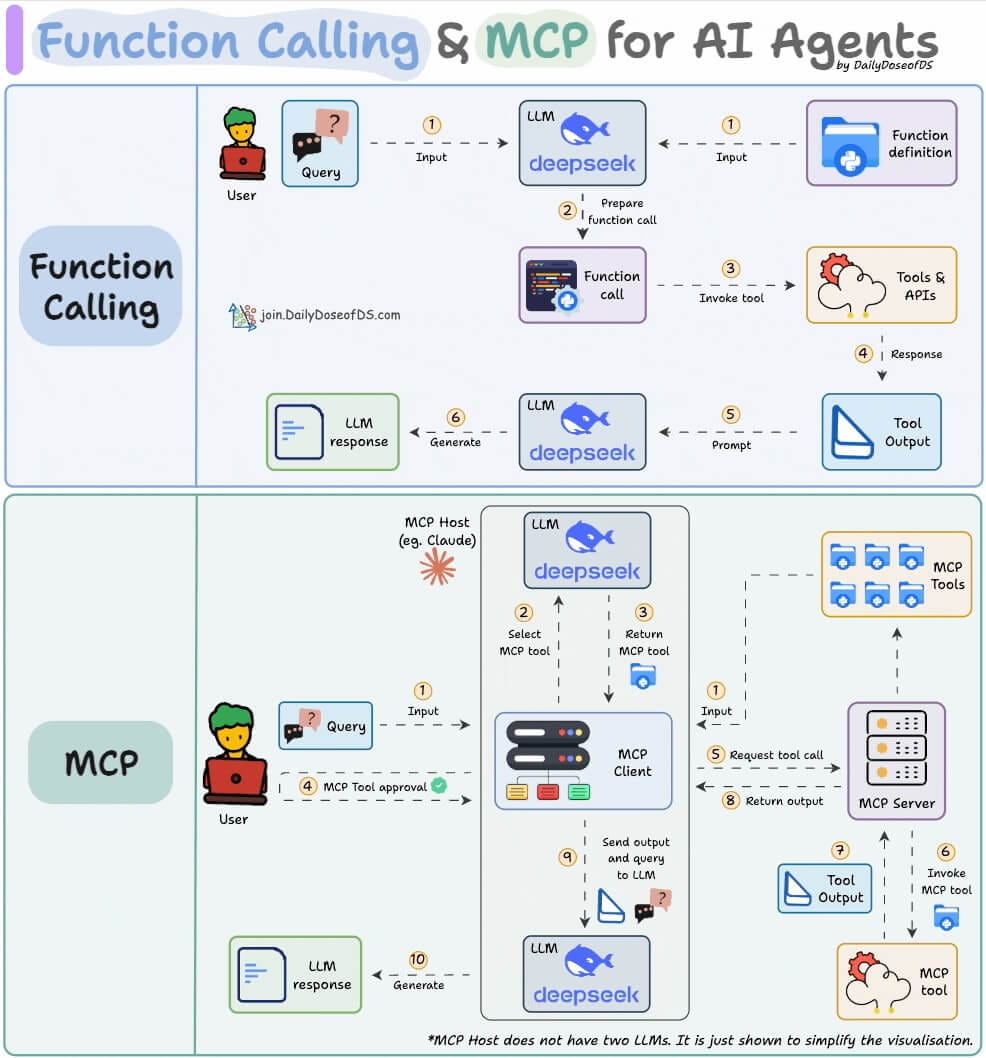
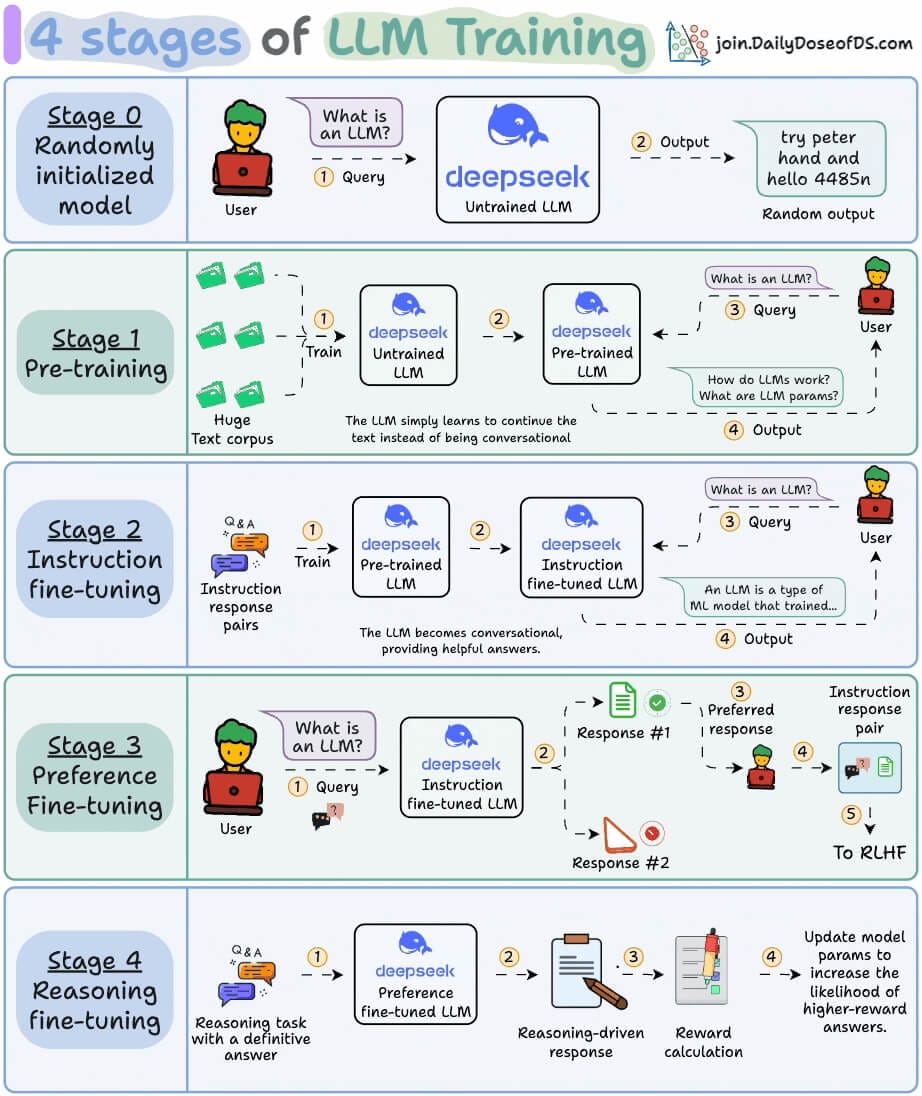
For AI professionals and enthusiasts who want to build a career on core expertise, not trends!
Master Full-Stack AI Engineering From First Principles to Production
Master Full-Stack AI Engineering From First Principles to Production
Master Full-Stack AI Engineering From First Principles to Production